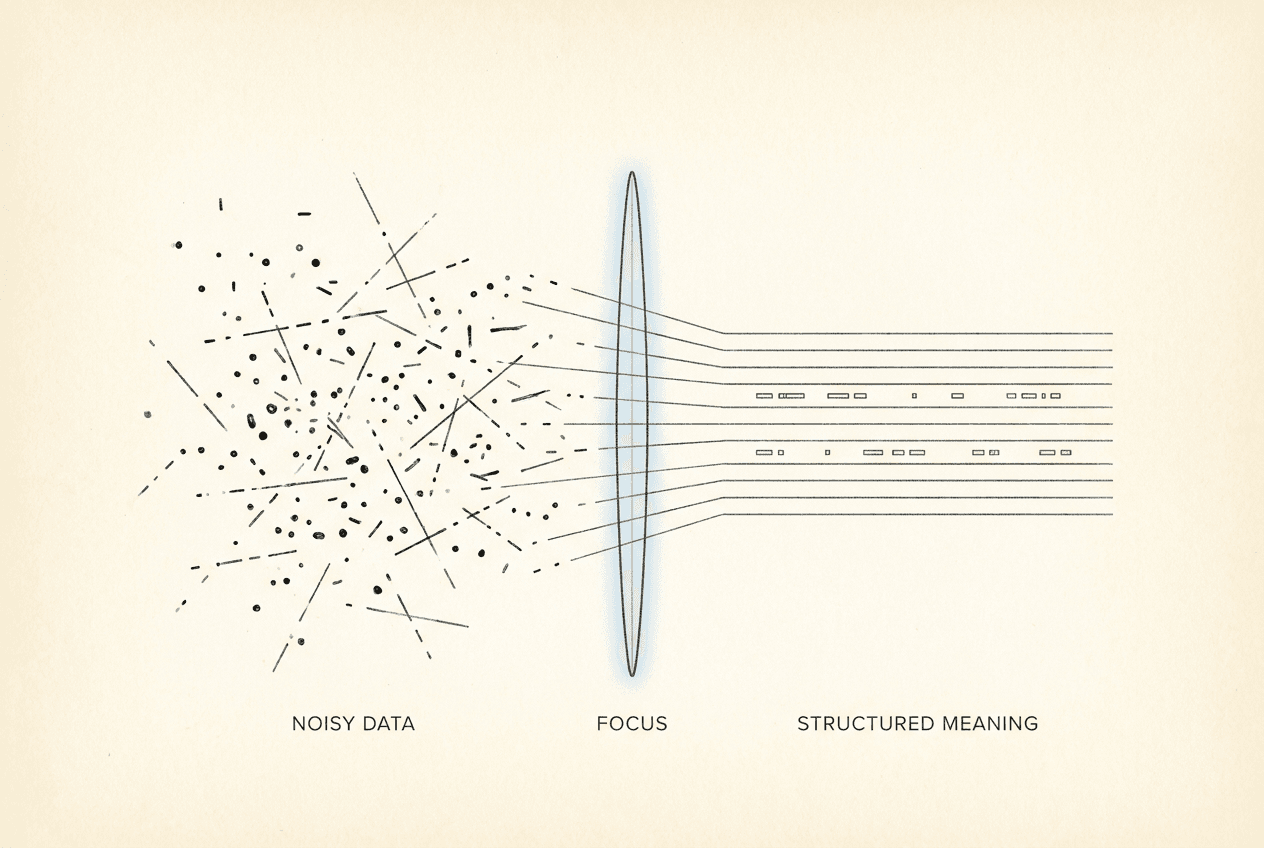
Thesis
Retrieval is not reasoning. A system can find the right text and still fail if the evidence is not structured into decisions.
This is a plain sans paragraph block for implementation notes. It supports bold text, italic text, underlined text, highlighted text, and strong custom weight without needing a heading.
This is the serif paragraph block for a more editorial sentence. Use it when a note needs a quieter explanatory passage with emphasis, texture, underlines, highlighting, or medium weighted text.
Why this problem matters
Most RAG systems are built around the assumption that better retrieval creates better answers. That is only partially true.
Retrieval can surface relevant context, but reasoning-heavy tasks require comparison, weighting, exclusion, confidence, and decision structure.
Where retrieval stops helping
The retrieved context may contain the answer, but the system still needs to decide which evidence matters, which evidence conflicts, and what action should follow.
The naive approach
The first version followed the standard pattern:
- Retrieve chunks from a vector store.
- Send retrieved context to the model.
- Ask for a final answer.
- Trust the model's reasoning.
The flow looked simple:
- Parse the input.
- Retrieve similar chunks.
- Build the prompt.
- Generate the response.
Comparison
| Naive Approach | Structured System |
|---|---|
| Retrieve chunks | Retrieve scoped evidence |
| Generate answer | Score decision-level checks |
| Return response | Return trace, confidence, and next action |
Confusion Matrix
Implementation note
Use score_run_id to track the full scoring pipeline and attach every output to an evidence trace.
Trace shape
The trace should make it possible to inspect the input, retrieved evidence, intermediate checks, confidence, and final recommendation.
Configuration
mandatory:
pass: 6.5
borderline: 5.5
optional:
weight: 0.35
confidence:
evidence_trace: required
Working rule
Treat retrieval as evidence collection, not as the reasoning layer.